
背景・目的
本記事では、既存データセットのWild Blueberry Yield Predictionというデータセットを用いてブルーベリーの収量推定モデルを構築します。また、実装はPython、R、MATLABの3言語を用いて各言語での実装例を示したいと思います。
実装例
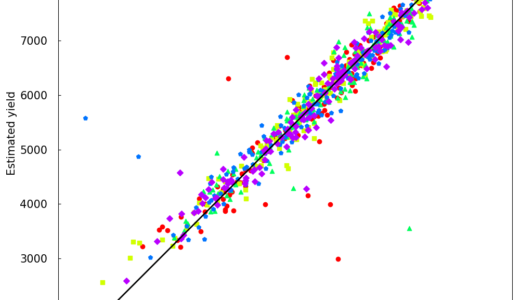
各言語での実装例でデータ分析の概要を示します。ブルーベリーの収量推定は、前処理で多重共線性を排除し、ランダムフォレストを用いて実施しました。
まとめ
今回は、Python、R、MATLABの3言語でランダムフォレストを用いたブルーベリーの収量推定の例を示しました。各コードで同じ処理が実行できますが、個人的にはずっと使っているPythonが好みです。一方で、多様なモデルについて一気に全てを試すことが可能なMATLABも好きです。また、Rも詳細な統計解析をする場合には、一番やりやすいと思います。結論としては、各言語は状況に合わせて使い分けるのが良いということです。

