
マーケティングミックスモデリング(Marketing Mix Modeling:以下、MMM)は、企業が複数のマーケティング活動の効果を定量化し、最適なリソース配分を決定するための手法です。これにより、広告やプロモーション、価格設定、流通戦略などの影響を分析し、売上やブランド認知度を向上させるためのデータドリブンな意思決定が可能になります。Pythonは、その豊富なライブラリと柔軟性により、MMMの実装に最適なツールです。本記事では、Pythonを用いてMMMを実行する超初歩的な方法について簡単に説明します。
データ収集と前処理
MMMの最初のステップは、必要なデータを収集し、前処理を行うことです。マーケティングデータには、広告費、プロモーション費、販売データ、競合情報、経済指標などが含まれます。今回は、ChatGPTでデータを生成しました。Salesデータ(Sales_data.csv)には、日付と売上が含まれています。Adデータ(Ad_data.csv)には、日付、Web広告費、TV CM費が含まれています。Pythonのpandasライブラリを使用すると、これらのデータを効率的に読み込み、処理することができます。
import pandas as pd
# データの読み込み
sales_data = pd.read_csv('Sales_data.csv')
ad_data = pd.read_csv('Ad_data.csv')次に、データの前処理を行います。例えば、日付データを適切な形式に変換し、必要に応じてデータのスムージングやノーマライゼーションを行います。
# データの結合
data = pd.merge(sales_data, ad_data, on='Date')
# 欠損値の処理
data.fillna(0, inplace=True)
# 日付データの変換
data['Date'] = pd.to_datetime(data['Date'])モデルの構築とトレーニング
データの前処理が完了したら、次にMMMのコアである回帰モデルを構築します。Pythonのstatsmodelsライブラリを使用すると簡単に回帰分析を実行できます。ここでは、売上を目的変数とし、広告費やプロモーション費を説明変数とする重回帰モデルを構築します。
import statsmodels.api as sm
# 説明変数と目的変数の設定
X = data[['Web', 'TV']]
y = data['Sales']
# 定数項の追加
X = sm.add_constant(X)
# 回帰モデルの構築とフィッティング
model = sm.OLS(y, X).fit()
# モデルのサマリー表示
print(model.summary())構築した重回帰モデルサマリーの結果は、以下の通りです。
モデルのトレーニングが完了すると、各マーケティング活動の売上に対する影響を定量化することができます。回帰係数は、それぞれの変数が売上に与える影響の大きさを示します。
OLS Regression Results
==============================================================================
Dep. Variable: Sales R-squared: 0.001
Model: OLS Adj. R-squared: -0.001
Method: Least Squares F-statistic: 0.3347
Date: Sat, 13 Jul 2024 Prob (F-statistic): 0.716
Time: 13:43:05 Log-Likelihood: -4084.7
No. Observations: 1000 AIC: 8175.
Df Residuals: 997 BIC: 8190.
Df Model: 2
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 199.8463 3.265 61.204 0.000 193.439 206.254
Web -0.0010 0.002 -0.427 0.670 -0.006 0.004
TV 0.0032 0.005 0.708 0.479 -0.006 0.012
==============================================================================
Omnibus: 7.018 Durbin-Watson: 1.880
Prob(Omnibus): 0.030 Jarque-Bera (JB): 6.926
Skew: 0.199 Prob(JB): 0.0313
Kurtosis: 3.091 Cond. No. 8.05e+03
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 8.05e+03. This might indicate that there are
strong multicollinearity or other numerical problems.モデルの評価と最適化
構築したモデルの評価を行い、必要に応じて最適化を行います。本記事の例では、モデルの評価にR²値や残差分析を使用します。R²値はモデルの適合度を示し、1に近いほどモデルのあてはまりが高いことを意味します。
# R²値の取得
r_squared = model.rsquared
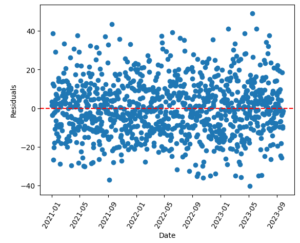
print(f'R²値: {r_squared}')残差分析を行うことでモデルの予測精度や異常値の検出が可能です。残差プロットを作成し、モデルの適合度を視覚的に評価します。残差プロットでは、縦軸の0に対して残差がどのようにばらついているかを確認します。残差が縦軸の0に対して均一に分散している場合、大きな問題はありません。残差プロットの中で他とは異なり大きく外れている値が少数ある場合、該当する値は外れ値である可能性があります。モデルの最適化には、変数の選択や非線形モデルの導入が考えられます。例えば、広告費と売上の関係が線形ではない場合、ロジスティック回帰やランダムフォレストなどの非線形モデルを試すことができます。これらの手法については、次回以降の記事で紹介予定です。
import matplotlib.pyplot as plt
# 残差プロットの作成
residuals = model.resid
plt.scatter(data['Date'], residuals)
plt.axhline(y=0, color='r', linestyle='--')
plt.xlabel('Date')
plt.ylabel('Residuals')
plt.title('Residual Plot')
plt.xticks(rotation=60)
plt.show()
まとめ
本記事では、Pythonを用いたマーケティングミックスモデリング(MMM)の超初歩の手法を説明しました。データ収集、前処理、モデルの構築とトレーニング、モデルの評価と最適化のプロセスを通じてマーケティング活動の効果を定量化し、最適なリソース配分を決定することができます。Pythonのライブラリを活用することでMMMを効率的に実行し、データドリブンなマーケティング戦略の立案に役立てることができます。実践では、データの質と量、モデルの適用範囲を考慮し、継続的な評価と改善を行うことが重要です。
なお、今回のデータは、ChatGPTを用いて生成したため、実際のデータとは大きくかけ離れています。ご了承ください。
